Meer over techniek
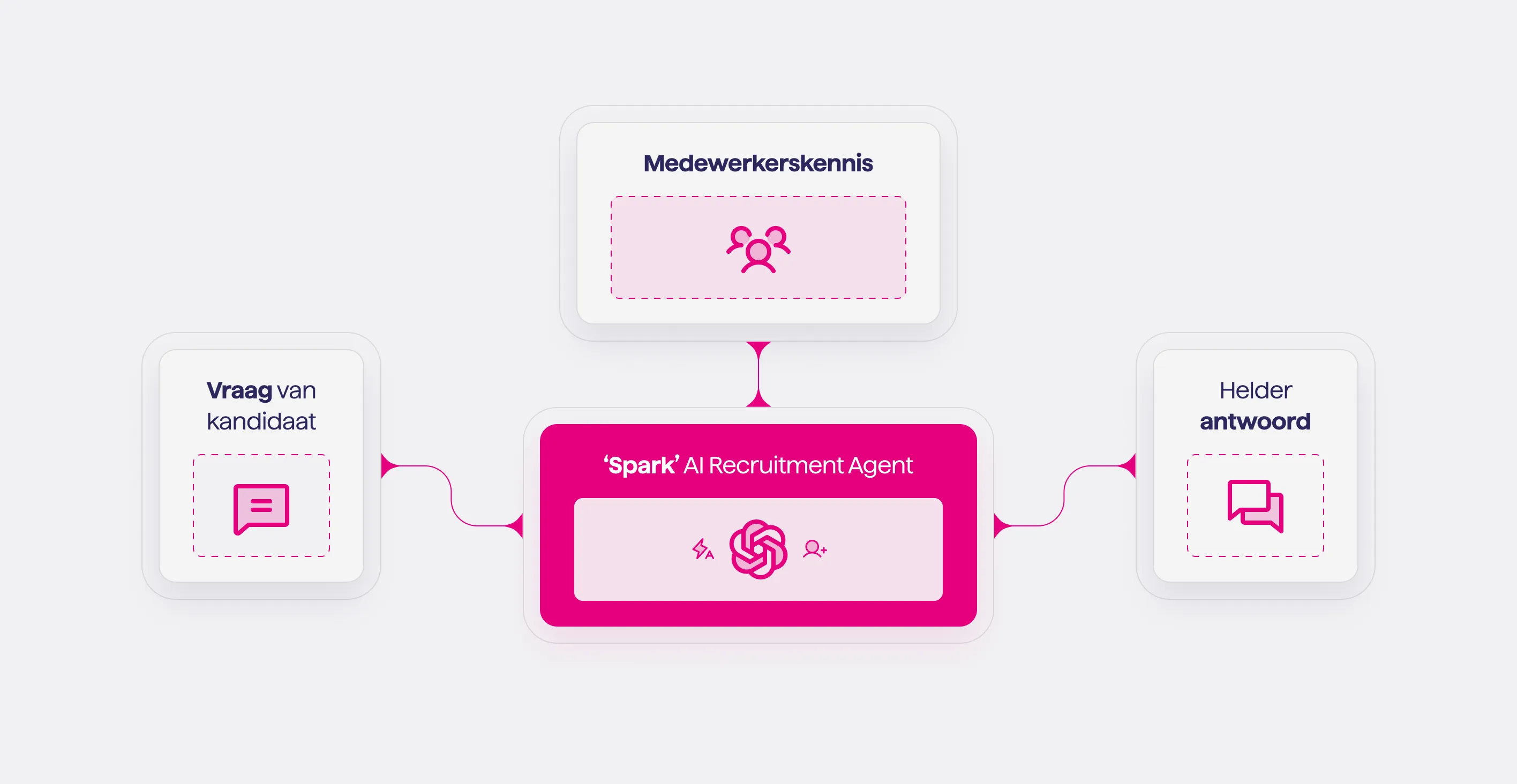
We hebben Spark ontwikkeld om kandidaatvragen betrouwbaar, schaalbaar en volledig op basis van jullie eigen content te beantwoorden.
Op welke techniek werkt Spark?
Spark is gebouwd op moderne AI-technologie, specifiek Large Language Models (LLM's) die zijn geoptimaliseerd voor natuurlijke conversaties. De chatbot maakt gebruik van een RAG-architectuur (Retrieval-Augmented Generation), wat betekent dat Spark niet alleen slim kan antwoorden, maar altijd eerst relevante informatie ophaalt uit je eigen kennisbank voordat er een antwoord wordt gegeven.
De backend is ontwikkeld in JavaScript en Python, met geautomatiseerde workflows die via REST API's en webhooks communiceren. Voor documentverwerking zetten we geavanceerde parsing-technologie in die PDF's, Word-documenten en spreadsheets intelligent kan analyseren en opdelen in doorzoekbare fragmenten.Gebruikt Spark ook externe bronnen of het internet?
Nee, Spark gebruikt geen externe bronnen of het internet. De agent antwoordt uitsluitend op basis van de content die je zelf hebt aangeleverd in de gekoppelde mappen. Dit is een bewuste architecturale keuze om te garanderen dat alle antwoorden accuraat, gecontroleerd en volledig in lijn met je bedrijfscommunicatie zijn.
Wat gebeurt er als Spark het antwoord op een vraag niet weet?
Wanneer Spark geen relevant antwoord kan vinden in de beschikbare kennisbank, is het systeem getraind om dit transparant te communiceren. In plaats van te hallucineren, zal Spark aangeven dat de specifieke informatie niet beschikbaar is en de gebruiker doorverwijzen naar de aangewezen contactpersoon met directe contactgegevens.
Alle gesprekken zijn daarnaast realtime inzichtelijk via een overzichtelijk dashboard. Je team kan meekijken met lopende conversaties en deze op elk moment overnemen wanneer persoonlijk contact gewenst is. Afgeronde conversaties worden opgeslagen en zijn ook inzichtelijk.Is Spark AVG-proof?
Spark is ontworpen met privacy by design en biedt de technische waarborgen die nodig zijn voor AVG-compliant gebruik.
Waar haalt Spark zijn informatie vandaan?
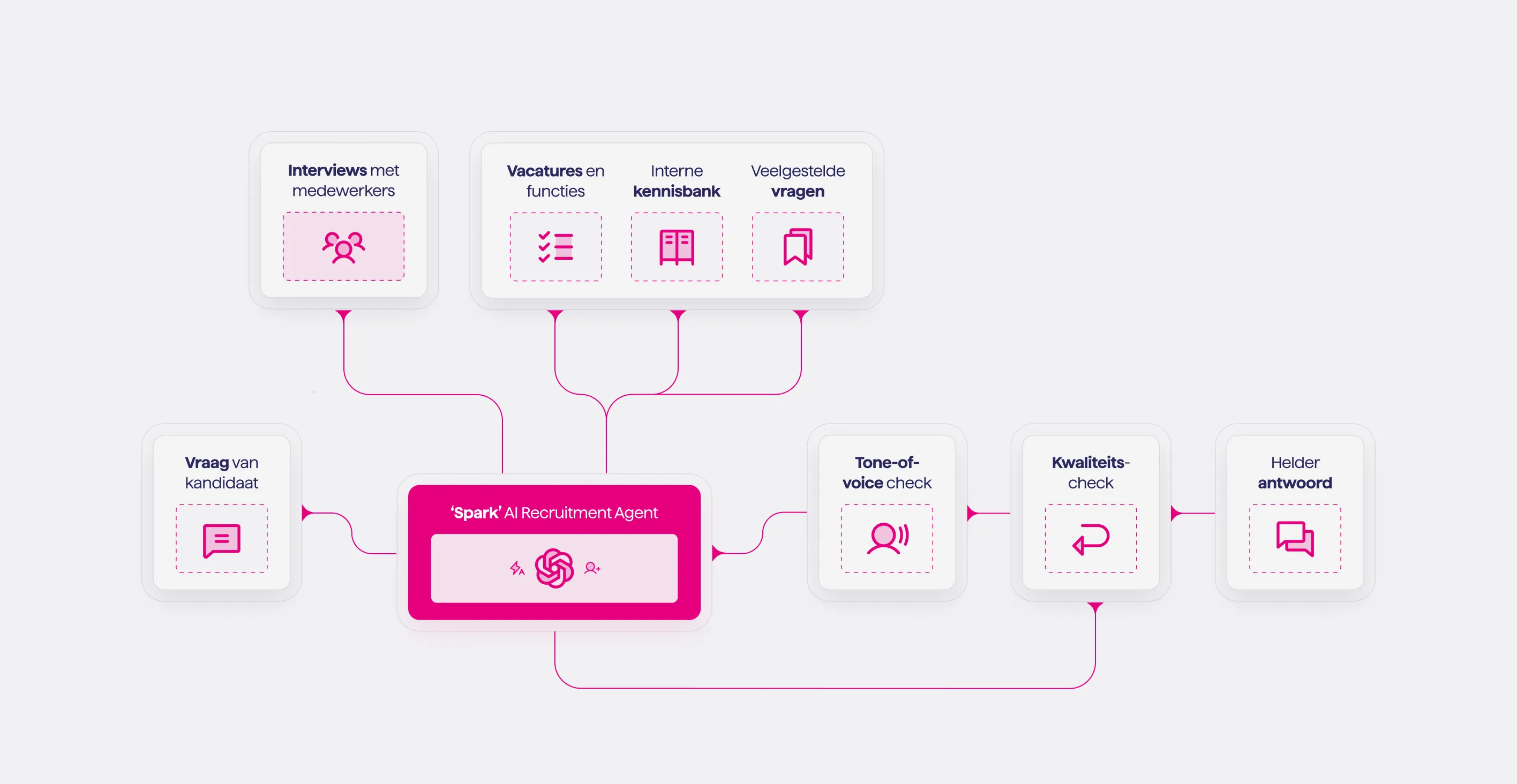
Spark haalt zijn informatie uitsluitend uit de documenten die je zelf aanlevert. Via een directe API-koppeling met Google Drive of Microsoft OneDrive/SharePoint monitort het systeem continu de mappen die je hebt aangewezen, bijvoorbeeld voor vacatures, functiebeschrijvingen, FAQ's, interviews met medewerkers en bedrijfsinformatie.
Zodra je een document toevoegt of wijzigt, detecteert het systeem dit automatisch via event-driven triggers. Het document wordt vervolgens verwerkt door onze Python-gebaseerde documentparser, omgezet naar vector embeddings via Google's Gemini embedding model en opgeslagen in een Pinecone vector database. Dit maakt razendsnelle semantische zoekopdrachten mogelijk, zodat Spark altijd de meest relevante passages vindt.Is mijn data veilig?
Ja, databeveiliging staat centraal in de architectuur van Spark. Je documenten blijven in je eigen Google Drive of Microsoft-omgeving staan; wij slaan geen originele bestanden op. Alleen de verwerkte vectorrepresentaties worden opgeslagen in een Pinecone database die specifiek voor jouw organisatie is ingericht in een eigen geïsoleerde omgeving.
Alle communicatie verloopt via versleutelde HTTPS-verbindingen en geauthenticeerde API-calls. Er worden geen gesprekken of documenten gedeeld met derden. De vector database draait op Europese servers (Google Cloud Platform, regio Europe West4 in Nederland) om te voldoen aan dataresidentie-eisen. Daarnaast is er rate limiting geïmplementeerd via Redis om misbruik te voorkomen.Hoe zorgen jullie dat Spark alleen antwoord geeft op basis van mijn content?
Dit is ingebouwd in de kernarchitectuur van Spark. De AI Agent is via zijn systeem prompt geconfigureerd om verplicht meerdere kennisbronnen te raadplegen voordat er een antwoord wordt gegeven: de FAQ-database, de content chunks uit je documenten, en actuele lijsten zoals openstaande vacatures.
Het systeem is expliciet geïnstrueerd om nooit antwoorden te genereren op basis van algemene modelkennis. Technisch wordt dit afgedwongen doordat het LLM alleen toegang heeft tot de retrieval-tools die jouw kennisbank doorzoeken. Daarnaast gebruiken we Cohere's neural reranker om uit de opgehaalde resultaten de meest relevante passages te selecteren, wat de precisie van antwoorden verder verhoogt.Welke persoonsgegevens worden verwerkt?
Tijdens chatgesprekken kunnen de volgende gegevens worden verwerkt: de inhoud van berichten, IP-adres en locatie (stad/land), browserinformatie en tijdstip van het gesprek.
N8N automatisering
Eenvoudig te integreren
Spark plaatsen we als overlay via een simpele embed op je werken-bij site en vacaturepagina’s. Kandidaten starten direct een gesprek in een vertrouwde chatinterface, in jullie tone-of-voice en huisstijl. Snel live, zonder dat je website op de schop hoeft.
Geautomatiseerd en zelflerend
Spark haalt informatie uit jullie eigen content en medewerkersinput, combineert de juiste bronnen en geeft een helder antwoord dat past bij de vraag. Alle gesprekken leveren inzichten op, waardoor Spark continu leert van data en feedback en steeds beter begeleidt richting een sollicitatie en passende match.
Technische waarborgen

Dataminimalisatie
Alleen noodzakelijke gegevens worden verwerkt. De kennisbank bevat geen persoonsgegevens, alleen jouw bedrijfsdocumentatie.
Recht op vergetelheid
Gesprekken kunnen permanent verwijderd worden, en wanneer je documenten verwijdert uit de bronmap worden de bijbehorende vectors automatisch verwijderd
Europese dataopslag
Europese dataopslag: Alle gegevens worden verwerkt en opgeslagen binnen de EU.
Versleutelde communicatie
Versleutelde communicatie: Al het dataverkeer gaat via HTTPS
Spark embed je eenvoudig op je website, werken-bij of vacature pagina, in eigen tone-of-voice en huisstijl



Aanpasbaarheid
De widget is volledig aan te passen aan je huisstijl: kleuren, welkomstbericht, vraagsuggesties en positie op de pagina. Technisch communiceert de frontend via beveiligde webhooks met onze backend-services, waar alle AI-verwerking plaatsvindt. Bezoekers zien alleen een strakke, intuïtieve en responsive chatinterface. De volledige technische complexiteit, van vector search tot LLM-aanroepen, blijft onzichtbaar op de achtergrond.
Integratie
Spark wordt geïntegreerd via een chat-widget die eenvoudig op je website kan worden geplaatst. Je ontvangt een JavaScript-embed die je (of je webbeheerder) toevoegt aan de HTML van je website, vergelijkbaar met hoe analytics-tools worden geïnstalleerd.

Boost je werken-bij site met Spark
Spark geeft kandidaten direct een antwoord dat voelt alsof het van een collega komt, gebaseerd op echte medewerkerverhalen.

of stuur een mail naar spark@effectgroep.nl